A year ago I duct-taped together, in a couple of days, an app for fun as an experiment. Without putting much thought into its design or scaleability. I then put it to run on a tiny ~$5 VPS. Not expecting more than a few users. It went on to gain users very slowly for a year. Until, fast forward to last month, STUDI’s traffic and users spiked nearly 20x in just a few days, and reached 2nd on AppStore’s education charts.
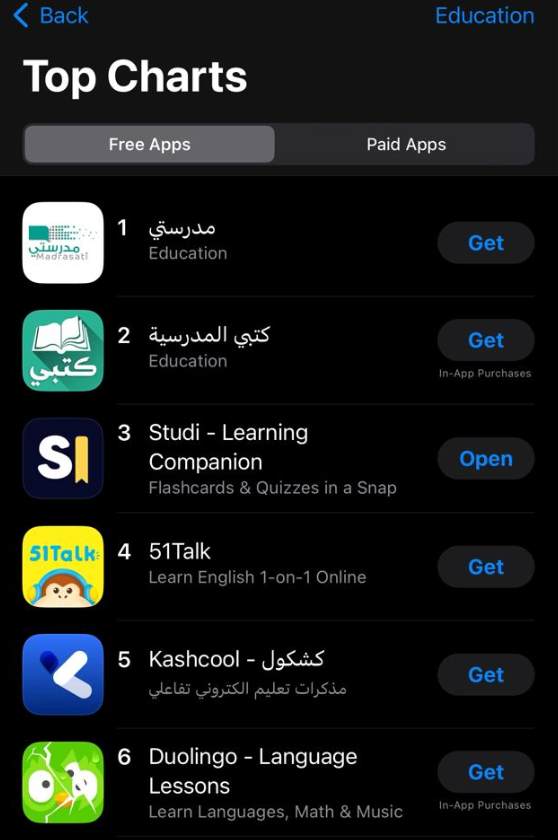
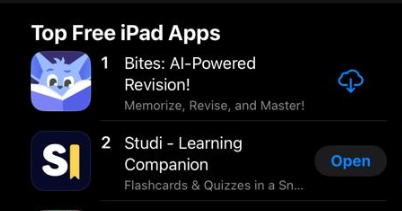
Under the sudden load, that tiny VPS started gasping for air, and it had to happen during finals season, when paying users—students using the app to study—needed it the most. Downtime or slowness at that point would’ve been … not good. The easiest solution was to scale vertically, so I did. But, as traffic kept climbing hour over hour, It became clear that continuing to vertically scale will not be a financially sustainable approach.

Adding to the mess, I didn’t have proper observability. Trying to figure out what’s breaking, what’s overloading the server, and where the bottlenecks were was a challenge in itself. Failures cascaded, everything affecting everything. The database, in particular, was struggling way more than it should’ve been. Managing it manually, handling backups, updates, and trying to scale it became a huge headache and timesink. My first thought was to migrate to a managed DB, but that wasn’t a quick win, and I needed those. So, I quickly reached out to a friend (@omar) for advice. He suggested tackling the basics as a the quickest move, find the slowest queries, optimize them, and add better indexing to buy some breathing room then do the migration. It was great advice, and it worked. It gave the server enough breathing room, at least for a few hours, and once things weren’t on fire, I went ahead and migrated the database. The migration itself was an adventure. It was a poorly set up, multi-node database with no safety nets. Moving that live, under pressure, was as fun as it sounds.
The traffic spike exposed all kinds of weak spots and bad design. The project was file processing heavy, doing file format conversions, extraction of images, and text, doing OCR, and classifcations, generating embeddings and a lot more. File processing performance was particularly bad taking 18 seconds on average, sometimes over 40 seconds while eating the CPU like there is no tomorrow. After handling the database migration, file processing was the next offender. I rewrote the file processing service in Go, focusing on concurrency and better core utlization. That, combined with a few more optimizations, brought processing times down to almost instant, even as the load 20x’ed.
And then, in the middle of all this, OpenAI, a core service in the project, went down for three hours. Peak load. Perfect timing. Customer support channels were on fire. When it finally came back, the queue was so backed up that jobs took forever to get picked up again to process, and rate limits meant workers couldn’t just start processing like nothing has happened, which made everything worse. Having a single point of failure is great /s. Luckily, one of the few areas I’d designed with some foresight was provider failovers (not really, I designed it that way to experiment with different LLMs at the time). While it was down, I added in some backups for OpenAI, and a few other services. But, those backups had different rate limits. This meant, to balance usage across all the different services, I had to implement dynamic rate limiting to make workers adjust limits and policies dynamically. I was already occasionally hitting OpenAI rate limits by that time.
Storage was another nightmare. I was using attached block storage. It started running out of inodes, file retention was breaking as storage started filling up way too quickly for it to keep up, and costs meant simply increasing the size was not a good approach, disregarding the many other issues with using a server attached block storage to do the processing. I migrated everything to S3-compatible stores with a multi-layered approach (hot, cold, warm) in a way that balances between both speed and cost. Which is another thing I needed to do without downtime.
Now the system is way more resilient. Stress tested. Better observability, better load separation, failovers in place. All while bringing costs down and improving performance across different areas of the system by many folds. It’s practically moving at the speed of light compared to the competitors.
I was lucky that this project required more demand for traffic, relative to other projects. Having a bad design, bad timing (I couldn’t afford any downtime when this happened), and a limited budget. All those combined with the increased load requirement per user meant I got to experience a stressed system and had to deal with optimization and scaling issues earlier than many at a similar scale. This thread from James Cowling explains this greatly.
If you want to get good building systems and databases you should go work for a bigger company or a startup with serious infra demands. It’s hard to develop excellence thinking about scale, correctness and architecture in an environment where these aren’t critical to the business
It’s certainly possible to be self-taught but the difference between good and great systems only shows up when systems are used and put under stress. Focusing on simplicity at all times and building sophistication only because that sophistication is demanded by real usage is key
Of course, I don’t think I’m anywhere near the scale he’s talking about. But, I got a glimpse of that and it was extremely valuable.
The point is, this whole self-inflicted experience—scaling, optimizing, load balancing, and firefighting without the conveniences (and IAMYAML struggles) of modern cloud providers, infra-as-code, container orchestrators, good observability—was painful. But it was also invaluable. Doing it manually under stress forced me to learn and understand the underlying systems and make decisions in a way I never would have if I’d relied on automated tools from the start, I could’ve moved everything to some cloud provider, paid more and masked the underlying issues—basically just swept them under the rug— and probably ended up dealing with another set of issues. As obviously, there are different challenges at different scales even with those tools. However, a lot of people my age started their careers in software when modern solutions for auto-scaling and managed services are posed as the default go to solutions. These tools are great, and many people are experts at using them. But without experiencing the pain they solve, it’s easy to miss the depth of what they really do.
The same goes for almost everything, take frontend work as an example. Many have started with reactive frameworks and have never worked on vanilla JavaScript or jQuery. Most, understandably, have a hard time even figuring out the tangled mess of ecosystem tools that come pre-packaged with each framework. While there’s nothing wrong with that depending on your goals. I think there’s a unique value in understanding the steps that got us here. I kind of envy those who grew with the tech. Learning it incrementally, step by step. Sure, it’s easier than ever to access resources and learn now; but I can’t help but feel like there’s a depth of understanding and appreciation that comes from starting small and building up without even having the option to skip into the future.
So, try doing things the manual—seemingly dumb—way. Build your own mini reactive framework, redis, docker, database engine, .. your own anything. Push a $5 VPS to its limits. Research something deeply. Look into the internals of complex tools. Learn the fundamentals. De-abstract layer by layer the things you feel you’re not smart enough to understand. Break things. Fix them. Every time I’ve chosen this path, I’ve gained a deeper understanding, in a shorter timeframe, with knowledge that sticks, far more than any other approach ever offered. I feel that with AI this is now more important than ever. Do not let it take over the joy of tinkering and learning. Even as someone who loves the craft, it’s very easy to slip into relying on AI to handle your thinking and problem-solving. But when used intentionally, AI can also be an incredible tool for learning and gaining a deeper understanding of almost anything far more efficiently than before.