There are many visual programming implementations out there that make approaching some specific tasks easier. One of which is Unreal Engine’s Blueprint’s system.

It provides game developers with a way to program visually by connecting different nodes. Each node taking in some inputs, and/or options, doing something with it, then outputting the results. You can also implement your own re-useable nodes using C++. It’s apparently turing complete too.
I wanted to make something similar for a project I’m working on, which brings us to: Data Flow Programming, Flow Based Programming, Node Graph Architecture, and a thousand other names.
In computer programming, flow-based programming is a programming paradigm that defines applications as networks of “black box” processes, which exchange data across predefined connections by message passing, where the connections are specified externally to the processes
In computer programming, dataflow programming is a programming paradigm that models a program as a directed graph of the data flowing between operations, thus implementing dataflow principles and architecture
I like to think of flow-based programming as a subset of data-flow programming, as the definition of the latter seems to be broader. Data-flow programming implements data-flow principles and architecture. Meaning that it implements something other than the conventional control-flow (instruction counter) computers we usually use. But of-course, Unreal Engine is not using data-flow hardware, and is not really emulating a “real” data-flow based paradigm. It is just a visual scripting implementation for a specific use case that tries to be as encompassing as possible for game devs.
I started implementing my own specific use case. I also wanted to have fun doing it so I avoided looking at unreal engine’s source code or any other implementations.
The General Idea
- I wanted to execute a simplified specialised program structured as a set of nodes, and connections.
- Each node can have a type, inputs, and outputs,
- Node type decides what the node does with the inputs.
- Each execution cycle should start with a clean(new) state?
- Each execution cycle should start when a special type of node (producer node) produces an output.
- A program can have multiple producer nodes.
Execution flow
The most interesting part in my opinion is building an effeicent nodes execution algorithm, a simple but fun problem. Where does it start from (entry point node?) What about multiple entry points? What happens if the nodes graph has a cycle?
Many graph theory concepts will be applicable here. Including a quick answer to the last question by restricting the program graph to be a DAG (Directed Acyclic Graph).
Let’s start with a possible node
type valueType string
type nodeType string
const (
PRODUCER_NODE nodeType = "PRODUCER"
ARITHMETIC_NODE nodeType = "ARITHMETIC"
CONSTANT_NODE nodeType = "CONSTANT"
)
const (
NUMBER_VALUE valueType = "NUMBER"
)
type value struct {
Type valueType
value interface{}
}
type values map[string]value
type additionalData map[string]interface{}
type connection struct {
nodeId string
outputId string
inputId string
}
type node struct {
id string
Type nodeType
inConnections []connection
outConnections []connection
additionalData additionalData
}
Each node will have an executor based on its type. Having the node implement an interface or some generic approach like a mapping of executors is a better way to do this. However for the sake of simplicity here is a switch statement.
func executeNode(n node) (executed bool, outputs values) {
switch n.Type {
case PRODUCER_NODE:
// ..
return true, values{"O1": {Type: NUMBER_VALUE, value: 5}}
// ..
// ..
default:
return false, nil
}
}
Given all the requirements. Say we have this simple adder program that takes two inputs
I have one input, one node that provides a constant value, and an adder node which will sum both inputs and output the result. In this case my input acts like a producer node which once an input is available will trigger an execution cycle.
So where should the execution start from? One naive approach could be to just:
- Loop through all nodes (no specific order).
- Attempt to execute node if not already executed.
- If all inputs required by the node are available, and the node is executed. Mark it as executed.
- Continue looping until all nodes are marked executed.
nodes := []node{
{id: "N1", Type: PRODUCER_NODE},
{id: "N2", Type: CONSTANT_NODE},
{id: "N3", Type: ARITHMETIC_NODE},
}
for {
isAllNodesExecuted := true
for _, n := range nodes {
executed, _ := executeNode(n)
if !executed {
isAllNodesExecuted = false
}
}
if isAllNodesExecuted {
break
}
}
Currently there is no way to pass around outputs, so this will not really execute. However, This non-determinsitc entry-point/s approach should work for the given program.
However, if any node in the program has some unpopulated/not-connected input it will loop forever. Another major issue is the performance. To execute a full cycle we have to loop through and attempt to execute each node multiple times. Like in the above program, It happened that the execution started at the adder node causing it to loop twice until all nodes were executed. Had the execution started on the constant value node the program would’ve executed in one iteration.
What about a deterministic entry-point/s approach? In which the program starts executing from multiple nodes, in no specific order also, that are known to be able to execute successfully with regards to their inputs.
Meaning that an entry-point node is any node that is able to execute with no connections.
For this approach:
- Loop through all nodes trying to find any node that fits the entry-point criteria and store it somewhere.
- Loop through all entry-point nodes and attempt to execute each one.
startingNodesIds := []string{}
for _, n := range nodes {
if len(n.inConnections) == 0 {
startingNodesIds = append(startingNodesIds, n.id)
}
}
// ... ..
for _, nodeId := range startingNodesIds {
executeNode(strategy, strategy.Nodes[nodeId], &executionTable)
}
This however misses one critical part. The execution is stopping at the entry-point/s and is not proceeding forward to any connections going out from it.
To solve this, we can recursively execute the nodes:
- When executing a node, loop through it’s out connections
- For each out conneciton, find the node its connected to and attempt to execute it.
func executeNodeRecursive(nodes map[string]node, n node.Node) {
if _, executed := // ..
{
// * Already executed, no-op
return
}
inputs := // ..
// * Execute node
outputs, executed, err := executors.Execute(n, inputs)
if err != nil {
// * Error executing, no-op
return
}
if executed {
// * Follow node outConnections recuresively
for _, outConnection := range n.outConnections {
executeNodeRecursive(nodes, nodes[outConnection.nodeId])
}
}
}
At this point the only thing missing is a method to populate node inputs with its connected outputs (some sort of node’s state)
At the beginning I made each node handle its own state, by storing its executed flag, inputs, and outputs. and letting each node populate its outConnections node’s inputs. But, in order to decouple the state for later usage, and to have some sort of time-travel debug-ability I decided to store the state of each cycle in a separate structure. The structure being just a simple mapping of the nodes and their outputs.
type executionTable map[string]values
func (extbl *executionTable) getNodeOutputs(nodeId string) (outputs values, executed bool) {
if outputs, executed := (*extbl)[nodeId]; executed {
return outputs, executed
}
return nil, false
}
func (extbl *executionTable) setNodeOutputs(nodeId string, outputs values) {
(*extbl)[nodeId] = outputs
}
Now when a node is executed, it returns an output, the executor then stores that output in the cycle execution table. Similarly, when a node being executed requires an input, the executor attempts to fetch that input from the cycle execution table. This abstraction made it easier to use a functional approach for executing the programs, which I find easier to reason about in the context of concurrent or multi-threaded applications, and overall less bugs to worry about. It also allowed me to experiment with other fun ideas later on.

func executeCycle(nodes map[string]node) (executionTable, bool) {
// * Init an empty execution table
executionTable := executionTable{}
// * Find starting nodes IDs (execution starts at nodes that have no inputs required)
// * e.g: constants, and producer nodes
startingNodesIds := []string{}
for _, n := range nodes {
if len(n.inConnections) == 0 {
startingNodesIds = append(startingNodesIds, n.id)
}
}
for _, nodeId := range startingNodesIds {
executeNodeRecursive(nodes, nodes[nodeId], &executionTable)
}
return executionTable, true
}
func executeNodeRecursive(nodes map[string]node, n node, executionTable *executionTable) {
if _, executed := executionTable.getNodeOutputs(n.id); executed {
// * Already executed
return
}
inputs := values{}
for _, inConnection := range n.inConnections {
if outputs, available := executionTable.getNodeOutputs(inConnection.nodeId); available {
if outputValue, ok := outputs[inConnection.outputId]; ok {
inputs[inConnection.inputId] = outputValue
}
} else {
// * Inputs considered not fully populated if any dependecy output is missing from the execution table
return
}
}
// * Execute node
outputs, executed, err := executors.Execute(n, inputs)
if err != nil {
// * Error executing
return
}
if executed {
executionTable.setNodeOutputs(n.id, outputs)
// * Follow node outConnections recuresively
for _, outConnection := range n.outConnections {
executeNodeRecursive(nodes, nodes[outConnection.nodeId], executionTable)
}
}
}
Now I can store each execution cycle table and backtrack, or move forward by providing the execution table at any point (step) in the cycle. Also, I could persist some outputs over multiple cycles if I wanted. If instead I coupled the state with each node, this would’ve been still possible but probably painful to implement, read, and debug.
So far this all works fine, I implemented a fake producer that runs in its own goroutine and produces some output every N ms, pre-populating whatever it has produced as part of the node, then triggering an execution cycle every N ms.

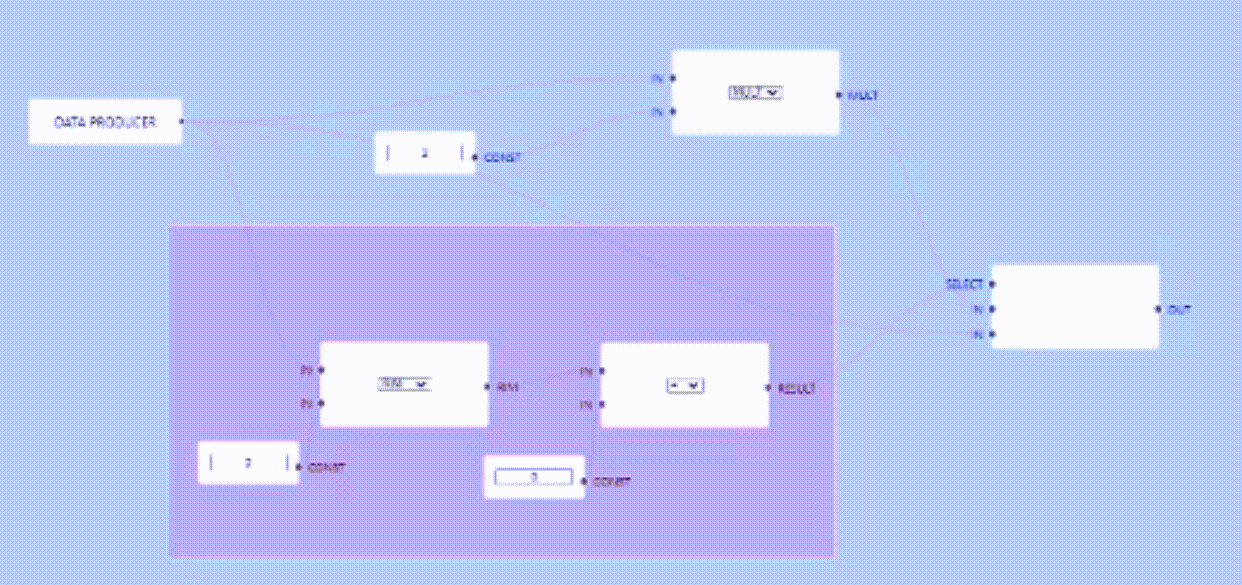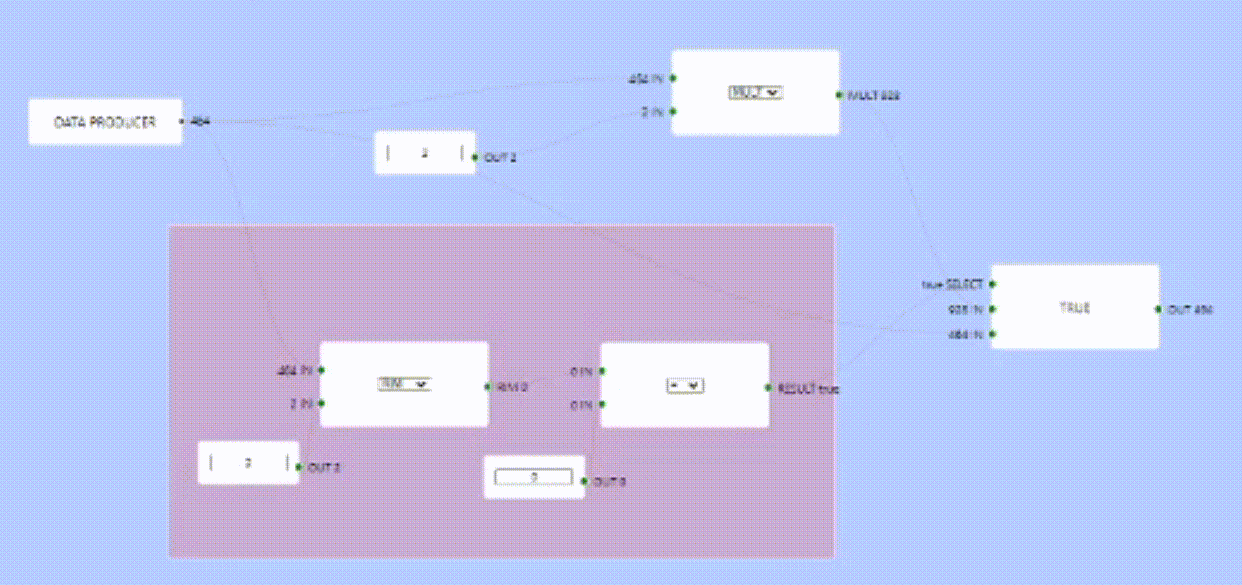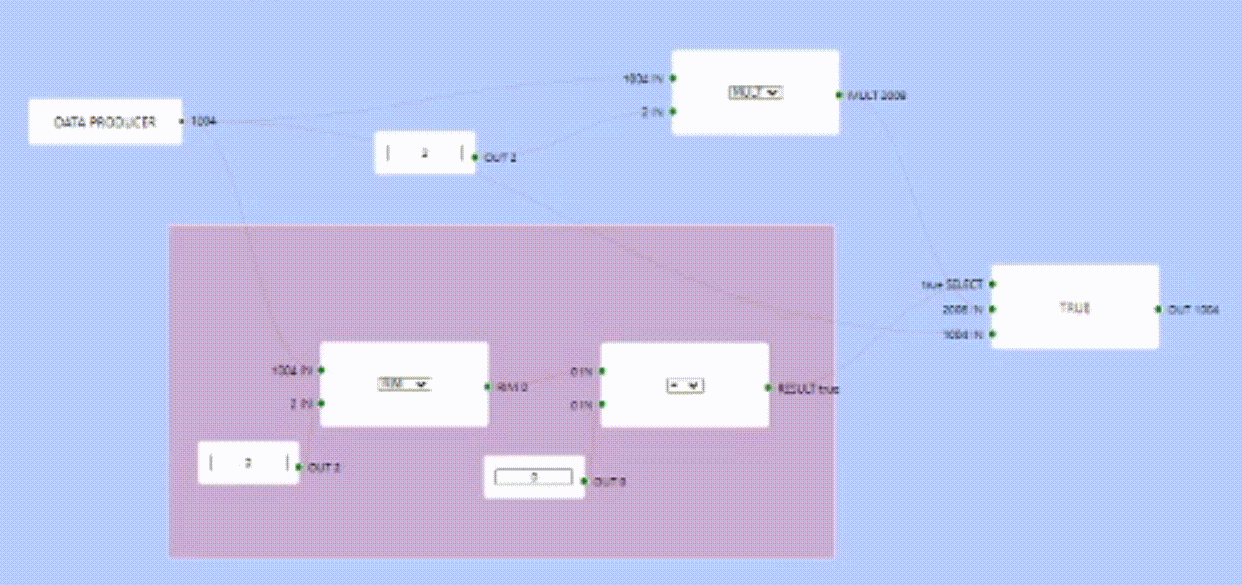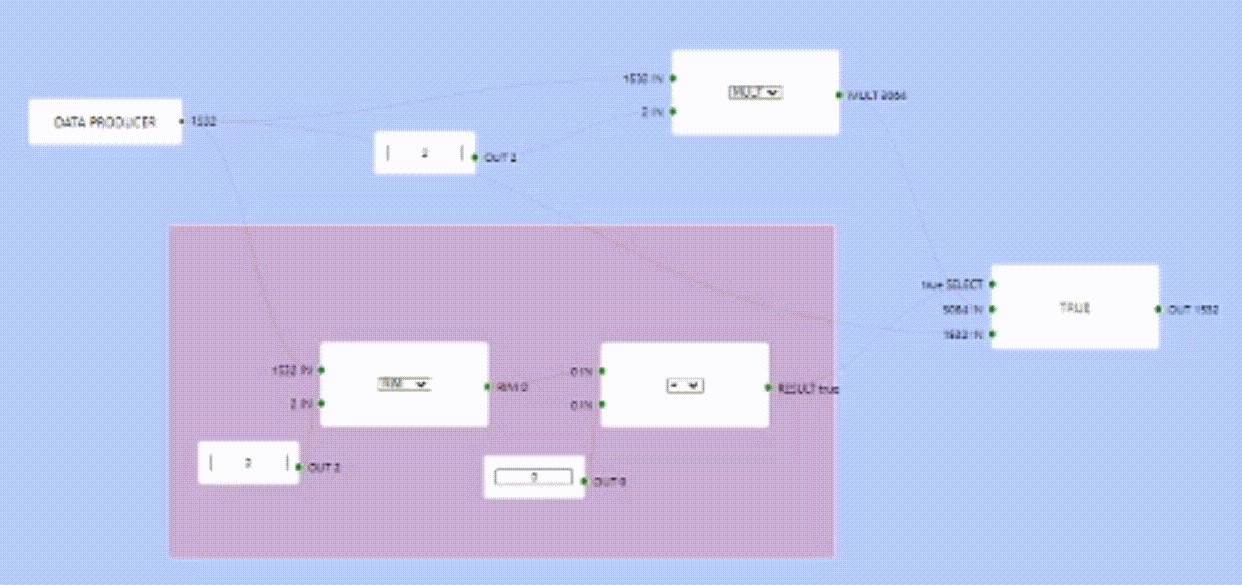
Multiple Producers
Since every producer runs in a separate goroutine, When it does produce if ever, is not guaranteed. I made it produce every N ms but this can change depending on the producer settings.
What If I wanted to have multiple producers with varying production rates? (this somewhat represent async I/O)
In a case where we have n producer nodes p1, p2, …, pn where for every producer p there is no path in the graph for all p1 to pn to reach any other p; everything will work just fine. Since what we have is essentially multiple program’s graphs each with its own producer.

However, in a program graph where we have multiple producers connecting to a single node. In other words, if any two producers in the program have a path that connects them, then the program will fail to fully execute unless both producers happen to have produced and pre-populated their outputs before triggering an execution cycle. But, this is simply not guaranteed to happen, since each producer will attempt to trigger an execution as soon as it have produced. Which in turn will simply just lock and restart the execution table every time.

For my specific use case, all I care about is that I execute the cycle with the latest produced output from each producer.
For example, consider that every producer is a ticker. One producer ticks every second, one ticks every minute, and another that ticks every 5 minutes, with all producers having paths to each other.
I want my program to execute only once it has all of the 3 necessary ticks. To do this, I made each producer store a rolling window of N ticks, calling back to trigger an execution whenever that ticks window has changed. When there is an attempt to execute while there are other producers ticks still missing, the execution does not happen but a ticks synchroniser is flagged for each producer. Once all producers in a program have ticked according to the synchroniser the execution is triggered and the synchroniser is reset.
type SafeTicksTracker struct {
mu sync.Mutex
v map[string]bool
}
func (c *SafeTicksTracker) Init(producerId string) {
c.mu.Lock()
c.v[producerId] = false
c.mu.Unlock()
}
func (c *SafeTicksTracker) Tick(producerId string) {
c.mu.Lock()
c.v[producerId] = true
c.mu.Unlock()
}
func (c *SafeTicksTracker) Reset() {
c.mu.Lock()
for producerId := range c.v {
c.v[producerId] = false
}
c.mu.Unlock()
}
func (c *SafeTicksTracker) IsFullyTicked() bool {
c.mu.Lock()
defer c.mu.Unlock()
fullyTicked := true
for _, ticked := range c.v {
if !ticked {
fullyTicked = false
}
}
return fullyTicked
}
func Stop(stopChans []chan bool) {
for _, stop := range stopChans {
go func(s chan bool) {
s <- true
}(stop)
}
}
func Start(nodes map[string]node) (stopChans []chan bool, ok bool) {
producersStopChans := []chan bool{}
ticksTracker := SafeTicksTracker{v: map[string]bool{}}
// * Find all producer nodes
producerNodes := map[string]node
for _, n := range nodes {
if n.Type == PRODUCER_NODE {
producerNodeCopy := n
producerNodes[n.id] = producerNodeCopy
ticksTracker.Init(n.id)
}
}
// * Starting producers
var nodesMapMutex sync.Mutex
for _, pn := range producerNodes {
// * Each producer will callback to this function (from the producer goroutine context) once its dataWindow is changed and ready to be used in a an execution cycle
started, stopChan := producer.Start(pn, func(producerNodeId string, dataWindow /*...*/) {
// * Updating the producer dataWindow with the newly produced data to be used in the execution cycle as outputs
// * A mutex is required to prevent conncurent map writes to the nodes map as dataWindows of different producers are being updated
nodesMapMutex.Lock()
nodes[producerNodeId].AdditionalData["dataWindow"] = dataWindow
nodesMapMutex.Unlock()
/*
* A concurrently safe ticks tracker is used to keep track of what producers have produced.
* this is implemented such that an execution cycle will only execute if all producers of that set of a program have produced
* the tracker is then reset to start the tracking again. So that another cycle of production is awaited from the producers
*/
ticksTracker.Tick(producerNodeId)
if ticksTracker.IsFullyTicked() {
ticksTracker.Reset()
// * Cycle execution starts
// * this also locks the producers from accessing the nodes map while the cycle is executing
nodesMapMutex.Lock()
executeCycle(nodes)
nodesMapMutex.Unlock()
}
}, func(producerNodeId string, err error) {
Stop(producersStopChans)
})
if !started {
// * If any producers failed to start for some reason, clean up by stopping all producers
Stop(producersStopChans)
return nil, false
}
// * Store producer stop channel to be used to stop the producer
producersStopChans = append(producersStopChans, stopChan)
}
return producersStopChans, true
}
Since each producer runs in a goroutine, attempting to modify a shared resource (producers synchroniser) some form of locking is necessary; that is why you see the mutex in the code.
Topological sorting
After implementing all of this of-course :dumb:, I realized that since the whole thing is a DAG. We can just do a topologcal sort on it and execute the nodes in that order. Technically, what I’ve done is basically the same. the executeNodeRecursive function executes nodes in a DFS manner.
Performance Remarks
Why Golang? Initially, I started the project (which is still a WIP) with Python for the backend, TypeScript for the frontend. Keep In mind that although I’m showing a simple loop producer in here. A producer can be anything, including some heavy I/O operations. So, when stress testing, Python’s GIL stepped in. I converted my implementation to be multiprocessing which was much better. But, overhead for memory, and initial start time for each producer (e.g when I wanted to restart thousands of them) was a major bottleneck.
Zero Down Time Releases?
I’m trying to keep the full picture of this side project a little vague here until it’s somewhat ready 😶🌫️🥷🏽, So this is a little hard to explain without the full details. But anyway, the program executor above runs as scaleable microservice, which in-turn runs those visual programs indefinitely.
A simplified idea for a new release: I could schedule some downtime, shutdown the service with its programs. Run the new one and restart all the programs from their latest execution tables.
However, for this project, a restarted program will not execute accurately if you just have a missing window of data between its stop and restart. For example, a program that has some producer producing every second was stopped for 10 minutes before restarting. Now there are 600 missing produced outputs in which an execution result might depend on.
I solved this using a program service-to-service hand-over/migration allowing all users to still run new programs, and at the same time have already running programs moved to the newly ran service with zero down time.
I will show this ✨ method in another post.
